| Overview |
| Screenshots |
Mission
Information fusion is the process of integration and interpretation of
heterogeneous data with the goal to get new information of a higher
quality. The key for an efficient and successful integration and
analysis of data from heterogeneous sources is an interactive and
iterative policy: relevant subsets of data have to be selected,
cleaned, transformed and integrated into a global schema. Next,
analysis and visualization techniques are applied. If the results are
not sufficient, this process will be repeated with different or
additional data, parameters, and methods.The InFuse system is designed as a database centered and component based middleware system to support efficiently Information Fusion tasks.
Features
Virtual data integration and analysis: Efficient support for data integration and analysis of large datasets is ensured by a tight coupling of the database system and analysis tools. This is achieved by using the FraQL multidatabase query engine.Uniform access to heterogeneous data sources: A CORBA-based adapter architecture and a global view mechanism provides a uniform abstraction layer to heterogeneous data sources.
Advanced data integration operations: Examples are resolving meta-data and instance-level conflicts
based on queries with "computed" tables and attributes as well as reconciliation functions.
Data transformation: Data transformation is supported by special operators (e.g. TRANSPOSE), extended grouping using user-defined functions as grouping criterion and user-defined aggregates.
Efficient analysis of large datasets: This includes generation of samples from the result of a query as well as selecting the "top k" results.
Multiple views: Various tabular and graphical views on existing and generated information sets are available. These support information investigation and exploration as well as controlling fusion execution.
Architecture
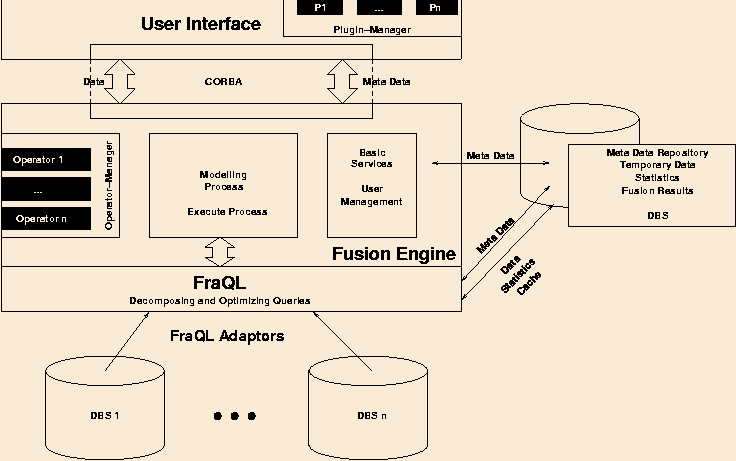
The global architecture of the InFuse system consists of three main parts: the fusion engine, the FraQL query processor and a front end for interactive graphical data analysis and exploration.
The fusion engine represents the central part of the system and is responsible for different tasks. As a fusion process consists of several dependent steps, the fusion engine manages the definition and persistence of processes and controls their execution. Process definitions as well as the states of running processes are stored in the central meta data repository. Therefore, several process instances with different parameter values can be executed for each definition at the same time.
Special operators (data mining or machine learning algorithms) can be loaded and unloaded dynamically into the system by the operator manager. These operators can be thought as a kind of stored procedures or functions and are restricted to use the mechanisms given by the fusion engine.
Besides these main features, the fusion engine provides additional services as user and error management. A CORBA based API is provided to connect to different front ends.
Furthermore, the fusion engine enables the user to perform the operations on sample data to evaluate for example convenient parameter settings before executing the analysis for the whole data set. The intermediate results can be shown and analyzed using various visualization techniques in the front end. In addition, the results can be materialized for later use. These features shall help the user to interactively and iteratively but also efficiently discover new information step-by-step.
To support these data analysis techniques on heterogeneous data sources the fusion engine relies on the features of the query processor called FraQL. A global object-relational view to heterogeneous date is offered by the query processor's adapter architecture. Several extensions in the query language provide easy to use integration and data preparation mechanisms.
Besides the integration steps, efficient data analysis is enabled by user-defined functions and aggregates, query optimization and techniques like multidimensional histograms and efficient sampling. For fast execution times a local cache for condensed statistics about the data and intermediate results is managed by the query engine. Hereafter, a virtual integration and data analysis is made possible by using techniques of the FraQL query processor.
The third part of the project is a front end, which provides a comprehensive collection of several ways of interacting with the system and exploring the data. The front end is extensible by a plug-in concept which allows adding new kinds of views. The tool is a full-featured administration and execution workbench. As it is connected to the fusion engine via a CORBA-interface, it can be replaced by specialized front-ends for different user groups.
Publications
- Oliver Dunemann and Ingolf Geist and Roland Jesse and Gunter Saake and Kai-Uwe Sattler.Informationsfusion auf heterogenen Datenbeständen, Informatik,
Forschung und Entwicklung, 2002, Volume 17, Number 3, pages 112-122,
- Oliver Dunemann and Ingolf Geist and Roland Jesse and Kai-Uwe Sattler and Andreas Stephanik.
A Database-Supported Workbench for Information Fusion: InFuse,
Advances in Database Technology - EDBT 2002, 8th International Conference on Extending Database Technology, Prague, Czech Republic, March 25-27, Proceedings, Editor: Christian S. Jensen and Keith G. Jeffery and Jaroslav Pokorn\'y and Simonas Saltenis and Elisa Bertino and Klemens Böhm and Matthias Jarke, pages 756 - 758, Springer, Lecture Notes in Computer Science, Volume 2287, 2002, ISBN: 3-540-43324-4 - O. Dunemann and I. Geist and R. Jesse and G. Saake and K. Sattler.
InFuse - Eine datenbankbasierte Plattform für die Informationsfusion, pages 9-25, Datenbanksysteme in Büro, Technik und Wissenschaft (BTW 2001), 2001, Editor: A. Heuer and F. Leymann and D. Priebe, Springer-Verlag